

Volume 3, Issue 3, 2025
Editorial
From Resource-Limited to Research-Rich: Unlocking the Scientific Potential of Developing Nations
Zuhair Dahham Hammood
For too long, the scientific narrative has been dominated by voices from wealthier nations. While their contributions are invaluable, the imbalance has left a vast reservoir of untapped knowledge and innovation in the developing world. Today, the time has come to shift the paradigm—from viewing developing countries as mere recipients of scientific progress to recognizing them as active producers of valuable, context-specific knowledge.
From Resource-Limited to Research-Rich is not a rhetorical flourish—it is a vision, a goal, and a challenge. It reflects a belief that scientific excellence is not the exclusive property of nations with abundant financial resources, but rather, a pursuit driven by curiosity, commitment, and community.
Developing countries, despite limited infrastructure and funding, are home to some of the most pressing health challenges—from endemic infectious diseases and rising non-communicable burdens to unique environmental and sociopolitical contexts. These challenges demand local insight, homegrown data, and context-sensitive solutions. The answers will not come from imported models alone. They must arise from within [1].
In this transformation, medical journals have a profound responsibility—not just as gatekeepers of knowledge, but as platforms for empowerment. Barw Medical Journal stands committed to this mission: to provide a voice to researchers working under constraints, to mentor and guide early-career scientists, and to uphold the integrity and quality of regional scholarship.
Success stories are already emerging. Across Africa, Asia, the Middle East, and Latin America, we are witnessing a rise in high-quality research led by local scientists. These efforts, often fueled by personal passion more than institutional support, prove that scientific ingenuity thrives even where resources are scarce [2].
However, more must be done. Governments must prioritize funding for health research. International agencies must listen more and dictate less. And academic partnerships must be based on equity, not extraction.
The path from resource-limited to research-rich is not paved overnight. It requires intentional investment, strategic collaboration, and relentless belief in the intellectual power of every nation. As we look ahead, let us remember: the next breakthrough in global health may very well come from a modest lab, in a hospital like ours, led by minds that simply needed a chance to be heard.
At Barw Medical Journal, we are here to amplify those voices.
Original Articles

The Effect of Clinical Knee Measurement in Children with Genu Varus
Kamal Jamil, Chong YT, Ahmad Fazly Abd Rasid, Abdul Halim Abdul Rashid, Lawand Ahmed
Introduction
Children with genu varus needs frequent assessment and follow up that may need several radiographies. This study investigates the effectiveness of the clinical assessment of genu varus in comparison to the radiological assessment.
Methods
In this study, relationship between clinical and radiographic assessments of genu varus (bow leg) in children, focusing on the use of intercondylar distance (ICD) and clinical tibiofemoral angle (cTFA) as clinical measures, compared to the mechanical tibiofemoral angle (mTFA) obtained via scanogram, the radiographic gold standard for assessing lower limb deformity. Clinical measurements (ICD and cTFA) were gathered along with the mTFA from scanogram radiographs. Reliability was tested between two observers, and Spearman’s correlation coefficient was used to evaluate the relationships between the clinical and radiographic measurements.
Results
The study involved 36 children with an average age of 6.3 years. There were strong intra-rater reliability for both observers (ICC 0.87 for observer 1, ICC 0.97 for observer 2) and excellent inter-observer agreement (ICC 0.97). Positive correlations were found between cTFA and mTFA (r² = 0.67, p < 0.001), between ICD and cTFA (r² = 0.53, p < 0.001), and between ICD and mTFA (r² = 0.62, p < 0.001).
Conclusion
This study suupports the idea that clinical methods may be sufficient for evaluation, minimizing the need for radiation exposure and offering a reliable alternative to radiography.
Exploring Large Language Models Integration in the Histopathologic Diagnosis of Skin Diseases: A Comparative Study
Talar Sabir Ahmed, Rawa M. Ali, Ari M. Abdullah, Hadeel A. Yasseen, Ronak S. Ahmed, Ameer M....
Introduction
The exact manner in which large language models will be integrated into pathology is not yet fully comprehended. This study examines the accuracy, benefits, biases, and limitations of large language models in diagnosing dermatologic conditions within pathology.
Methods
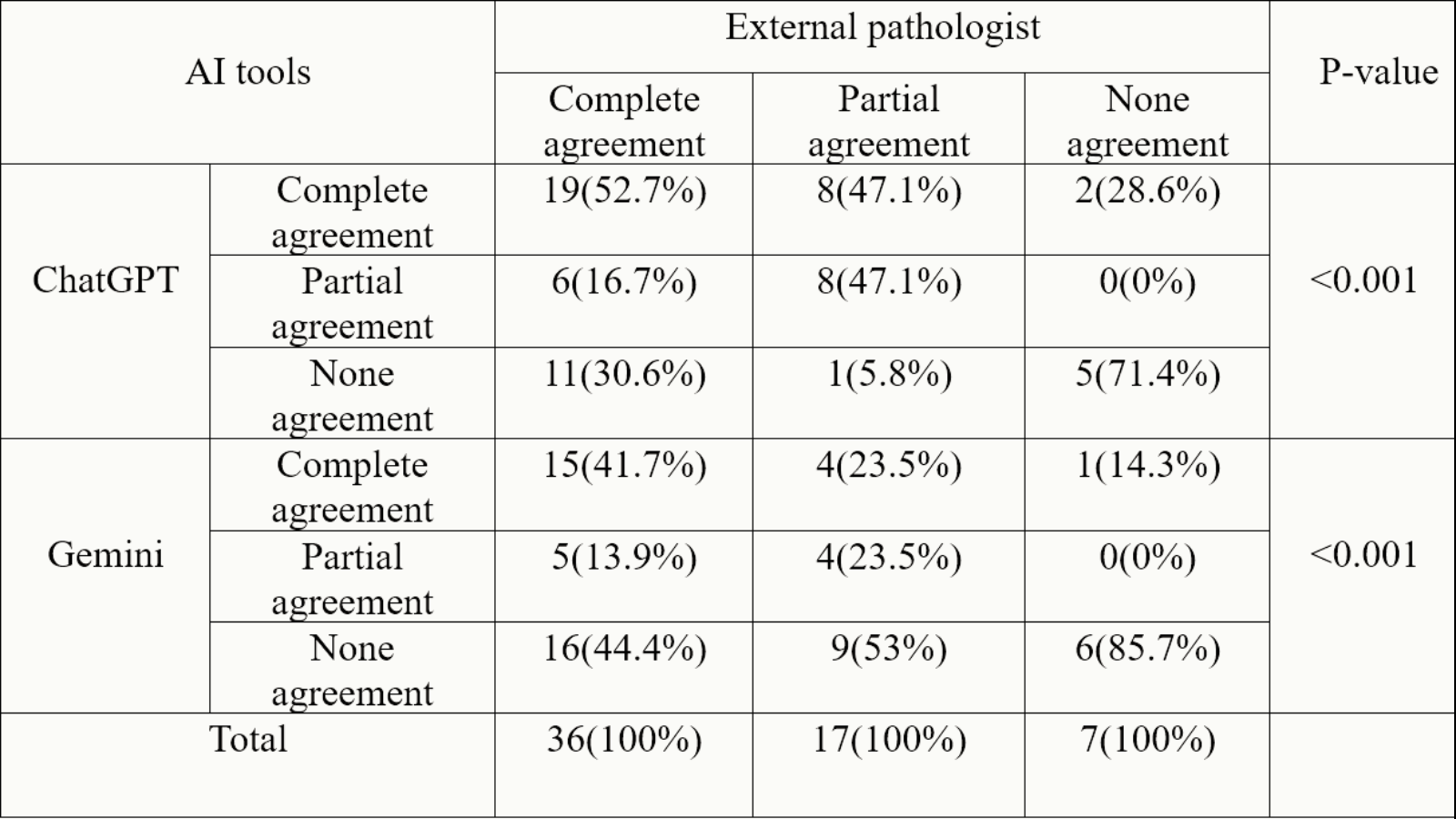
A pathologist compiled 60 real histopathology case scenarios of skin conditions from a hospital database. Two other pathologists reviewed each patient’s demographics, clinical details, histopathology findings, and original diagnosis. These cases were presented to ChatGPT-3.5, Gemini, and an external pathologist. Each response was classified as complete agreement, partial agreement, or no agreement with the original pathologist’s diagnosis.
Results
ChatGPT-3.5 had 29 (48.4%) complete agreements, 14 (23.3%) partial agreements, and 17 (28.3%) none agreements. Gemini showed 20 (33%), 9 (15%), and 31 (52%) complete agreement, partial agreement, and no agreement responses, respectively. Additionally, the external pathologist had 36(60%), 17(28%), and 7(12%) complete agreements, partial agreements, and no agreements responses, respectively, in relation to the pathologists’ diagnosis. Significant differences in diagnostic agreement were found between the LLMs (ChatGPT, Gemini) and the pathologist (P < 0.001).
Conclusion
In certain instances, ChatGPT-3.5 and Gemini may provide an accurate diagnosis of skin pathologies when presented with relevant patient history and descriptions of histopathological reports. However, their overall performance is insufficient for reliable use in real-life clinical settings.
Defining the Scientist: A Consensus-Based Approach
João Gama, Marko Mladineo, Shelina Bhamani, Behzad Shahmoradi, Victoria Samanidou, Alexander S....
Introduction
The term “scientist” lacks a universally accepted definition, reflecting the evolving, interdisciplinary nature of scientific work and posing challenges for recognition, communication, and policy. This study aims to develop consensus-based definitions of the term “scientist” by engaging experienced scholars across diverse fields.
Methods
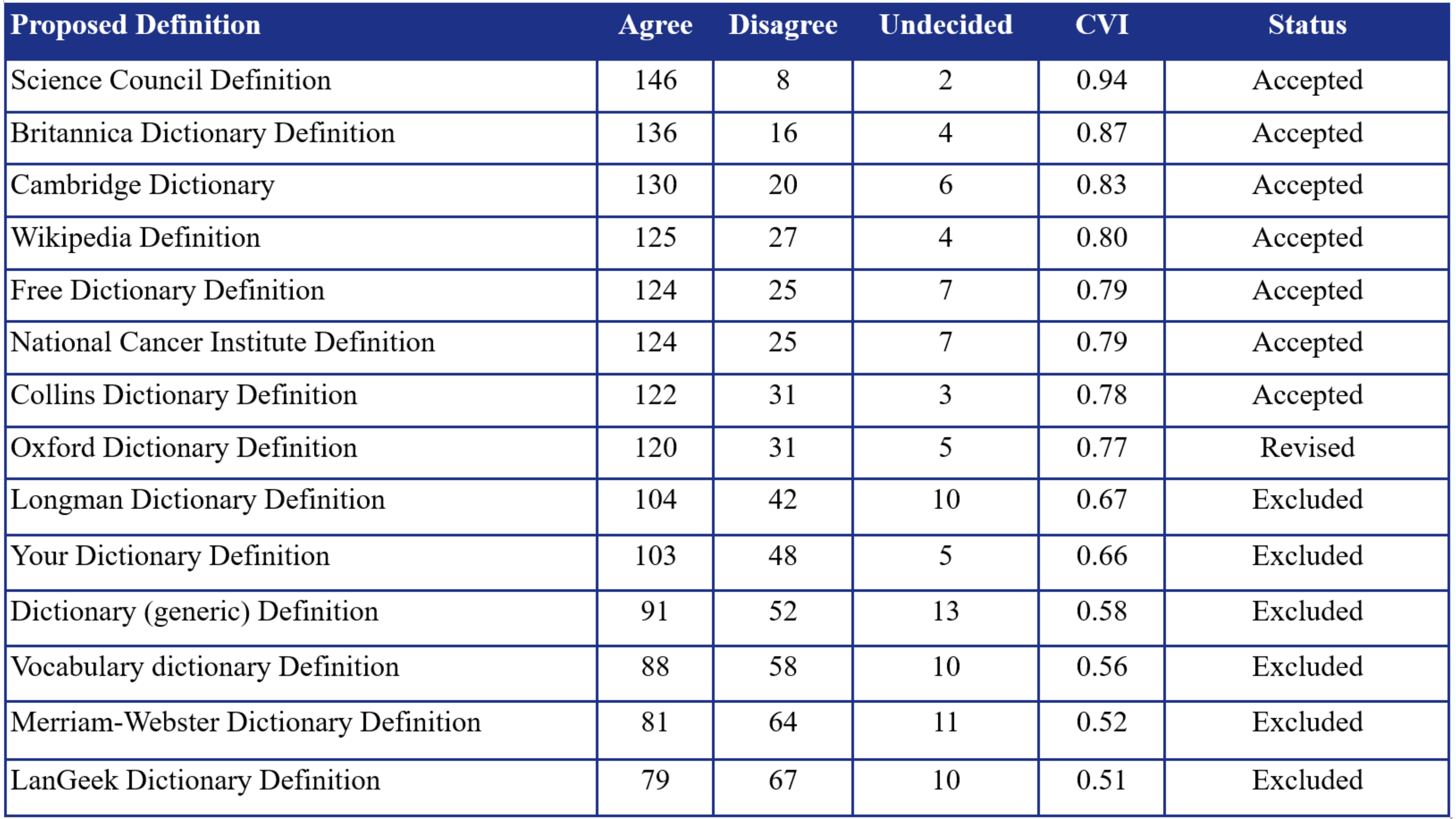
This study involved 156 scholars, each with at least 1,000 citations, recruited via convenience sampling. Fourteen scientist definitions, derived from literature and expert input, were assessed using a nine-point Likert scale via a structured google forms survey. The sample size was calculated using G*power (effect size = 0.5, power = 0.95), requiring at least 80 participants. Content Validity Index (CVI) was used for analysis. Definitions scoring ≥0.78 were accepted and included for final analysis, 0.70–0.78 were revised and re-evaluated, and <0.70 were excluded. Participation was voluntary and anonymous, ensuring ethical compliance and confidentiality.
Results
Of the 14 proposed definitions, six (42.9%) were excluded (CVI < 0.70), seven (50.0%) were accepted (CVI > 0.78), and one (7.1%) underwent revision (CVI 0.70–0.78). The highest-rated definitions were refined into two consensus-based versions: a short definition (“A scientist is a person who conducts research”) and a detailed one emphasizing hypothesis formulation and knowledge dissemination. Final validation yielded CVIs of 0.82 and 0.84, respectively, confirming strong expert agreement on both definitions.
Conclusion
This study developed two validated definitions of “scientist” emphasizing systematic research and knowledge dissemination. These definitions clarify the concept of scientific identity, providing a flexible yet rigorous framework applicable across academic, interdisciplinary, and policy-making contexts.

Management of Lower Limb Varicose Veins Using Endovenous Laser Ablation, Micro-Phlebectomy, and Sclerotherapy Using Multimodal Analgesia
Fahmi H. Kakamad, Fuad E. Fuad, Soran H. Tahir, Ayoob A. Mohammed, Rezheen J. Rashid, Hiwa O....
Introduction
Previously, the conventional surgical procedure of high-ligation and saphenous stripping was commonly used to treat varicose veins (VVs). However, contemporary advancements have led to the rapid evolution of VV management. This study shares a single center's experience in treating patients with lower limb VVs through endovenous laser ablation in combination with phlebectomy and sclerotherapy using multimodal analgesia.
Methods
This case series study included consecutive patients diagnosed with lower limb VVs. The inclusion criteria encompassed VVs categorized from score C1 to C6 clinical, etiologic, anatomic, and pathophysiological (CEAP), saphenofemoral incompetence, and patients aged between 18 and 75.
Results
A total of 153 patients were enrolled. The majority were female (73.0%), resulting in a female-to-male ratio of 2.73:1. The age of patients ranged from 18 to 73 years, with a mean age of 40.8 ± 11.7 years. Regarding post-procedural complications, wounds developed in 25 patients (16.3%), making it the most common complication, while thrombophlebitis occurred in 15 cases (9.8%), skin discoloration in nine cases (5.9%), and recanalization and DVT each in a case (0.7%). Due to extensive varicose veins, 31 patients (20.0%) required a sclerotherapy session six weeks after the operation. Patients could return to routine daily activities within 4 to 10 hours. Overall, the patient satisfaction rate (complete and partial) was 85%. Only a case of recurrence (0.7%) was reported after a one-year follow-up.
Conclusion
Endovenous laser ablation, in combination with phlebectomy and sclerotherapy using multimodal analgesia, may yield a satisfactory outcome in patients with moderate to severe VVs.
Review Articles
Chest Wall Hydatid Cysts: A Systematic Review
Fahmi H. Kakamad, Harem K. Ahmed, Ali H. Hasan, Ahmed H. Ahmed, Ayoob A. Mohammed, Dindar H....
Introduction
Given the rarity of chest wall hydatid disease, information on this condition is primarily drawn from case reports. Hence, this study systematically reviews the disease's manifestation and management.
Methods
Google Scholar was searched with the following keywords: (hydatid OR hydatidosis OR tapeworms OR echinococcosis OR echinococcus OR granulosus AND chest OR wall OR thoracic OR thorax OR rib OR sternum OR sternal OR cartilage OR intercostal OR extra-pulmonary). Inclusion criteria involved a confirmed diagnosis of chest wall hydatid cyst. Only English-language studies published in legitimate journals were included.
Results
The reported cases were primarily from Turkey (41.5%). The mean age of the patients was 39.7 ± 17.1 years, with a male predominance (56.9%). The most common clinical presentations were swelling (47.1%) and chest or abdominal pain (45.1%). Only 10 cases (19.6%) had reported a history of animal contact. Among those with documented residency (35.3%), 16 (31.4%) resided in rural areas. The average mass size on the CT scan was 7.5 ± 2.4 cm. Surgery was the treatment of choice, with thoracotomy performed in 37.3% of cases, video-assisted thoracoscopy in 1.9%, and the surgical technique not specified in 60.8% of cases. The mean hospital stay was 8.6 ± 4.4 days, and no recurrences were reported.
Conclusion
Despite its rarity, chest wall hydatid cyst may have a good prognosis with few complications. Given its often-nonspecific presentation, reviewing the patient's medical history may help establish an accurate provisional diagnosis.
Are Cervical Ribs Indicators of Childhood Cancer? A Narrative Review
Fahmi H. Kakamad, Lawand Ahmed Sharif, Ahmed H. Ahmed, Sakar O. Arif, Omed M. Hussein, Azad S....
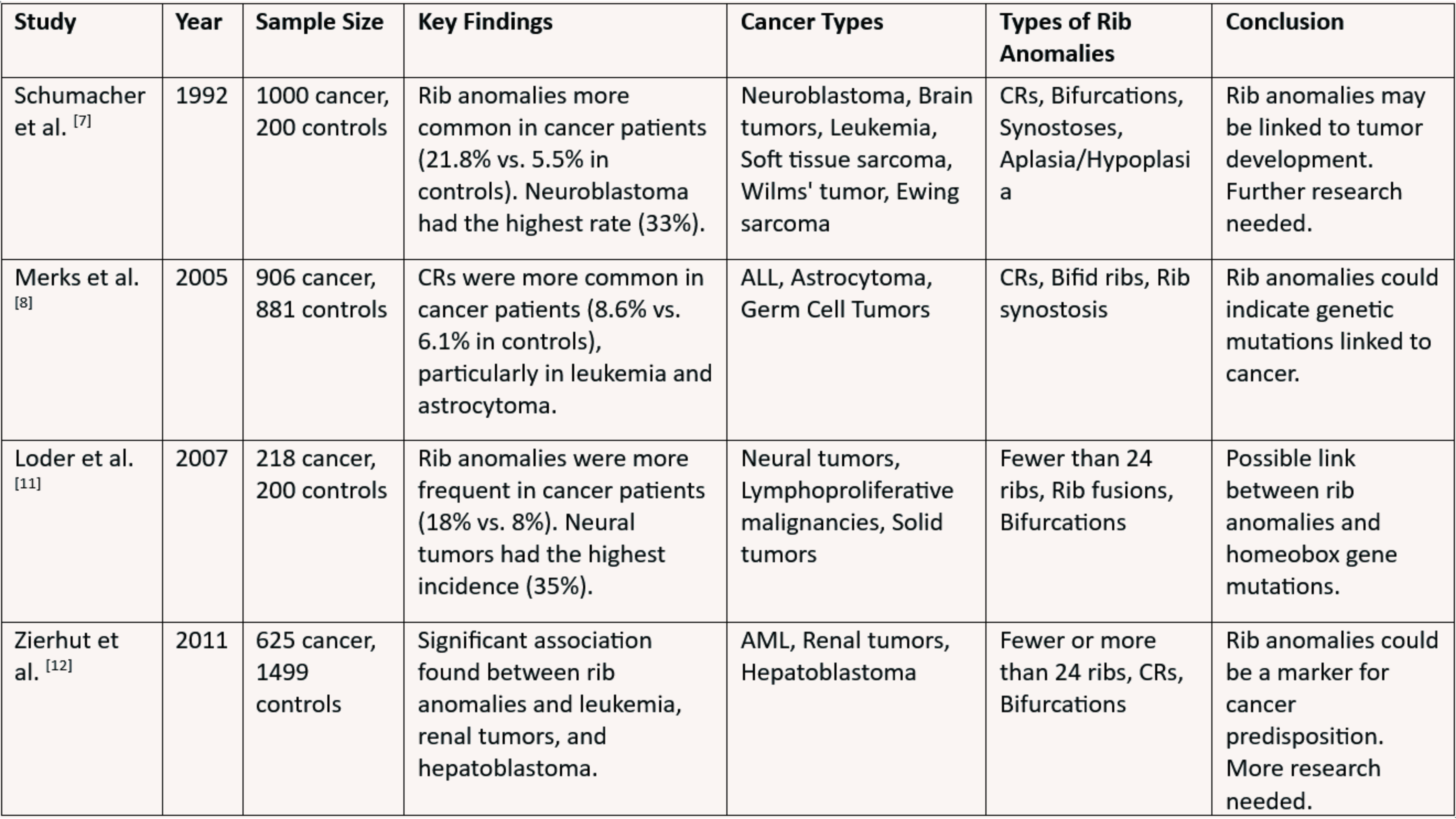
A cervical rib (CR), also known as a supernumerary or extra rib, is an additional rib that forms above the first rib, resulting from the overgrowth of the transverse process of a cervical vertebra. Increasingly recognized as a potential marker of developmental disruptions and genetic instability, CRs are believed to arise from mutations in homeobox (Hox) genes that influence axial skeletal development. While often asymptomatic, CRs have been linked to thoracic outlet syndrome and a higher prevalence in individuals with certain childhood cancers. Studies have reported associations between CRs and malignancies such as neuroblastoma, brain tumors, leukemia, sarcomas, Wilms tumor, and germ cell tumors, suggesting possible shared embryological pathways or genetic predispositions. However, conflicting research findings highlight inconsistencies in these associations, underscoring the need for further investigation. This review aims to assess the association between CRs and childhood cancers by examining prevalence rates, exploring genetic and developmental links, evaluating inconsistencies in existing research, and identifying gaps for future study to clarify the clinical significance of CRs in cancer risk assessment.
Presentation and Management of Cervical Thoracic Duct Cyst: A Systematic Review of the Literature
Fahmi H. Kakamad, Dilan S. Hiwa, Aland S. Abdullah, Hiwa O. Baba, Aso S. Muhialdeen, Sarwat T....
Introduction
Thoracic duct cysts are an uncommon phenomenon, especially within the cervical region. Due to its limited reported cases, very little is known about its etiology, presentation, and management. This systematic review is conducted to shed light on the ways the cyst presents and the outcomes of different treatment regimens.
Methods
The EMBASE, CINAHL, PubMed/MEDLINE, Cochrane Library, and Web of Science databases were thoroughly screened to identify any studies published in English up to March 24th, 2024.
Results
The average age of the patients was 47.8 years, with 9 (56.3%) females in the study population. The mean size of the cysts was 5.99 cm, and the most common symptom was pain, present in 5 (31.3%) patients. The most common management approach chosen for 6 (37.5%) patients was simple follow-up and observation, followed by surgical excision in 5 (31.3%) patients.
Conclusion
Patients with thoracic duct cervical cysts may be asymptomatic or present with pain. Both surgical excision and conservative management may yield satisfactory outcomes.
Case Reports
Renal Ewing Sarcoma: A Case Report and Literature Review
Rebaz M. Ali, Zhino Noori Hussein, Jalil Salih Ali, Bnar Sardar Saida, Saman S. Fakhralddin, Rawa...
Introduction
Primary renal Ewing sarcoma is an extremely rare and aggressive tumor, representing less than 1% of all renal tumors. This case report contributes valuable insights into the challenges of diagnosing and managing this rare malignancy, particularly when it presents with atypical symptoms.
Case presentation
A 30-year-old female presented with intermittent grassy green-colored urine, later turning into red, with a headache and no abdominal pain. Clinical examination revealed elevated blood pressure. Imaging studies, including ultrasound and computed tomography scans, identified a large, heterogeneous mass in the left kidney with invasion into the renal vein and lymph nodes, leading to a staging of T3N1M0. The patient underwent a left radical nephrectomy, with pathology confirming a Grade 2 primary Ewing sarcoma / primitive neuroectodermal tumor of the kidney. Despite aggressive treatment with adjuvant chemotherapy, stable metastatic deposits persisted, indicating ongoing active disease.
Literature review
Ewing sarcoma typically occurs in bones but can occasionally arise in solid organs such as the kidney. Most patients present with non-specific symptoms, and the disease often remains undiagnosed until it has metastasized. Current treatment involves multimodal therapy, including surgery and chemotherapy, but prognosis remains poor, especially in cases with metastasis.
Conclusion
This case underscores the complexity of diagnosing and treating primary renal Ewing sarcoma. Persistent metastasis despite treatment highlights the need for vigilant monitoring. Further genetic profiling could enhance understanding and management of this rare condition.
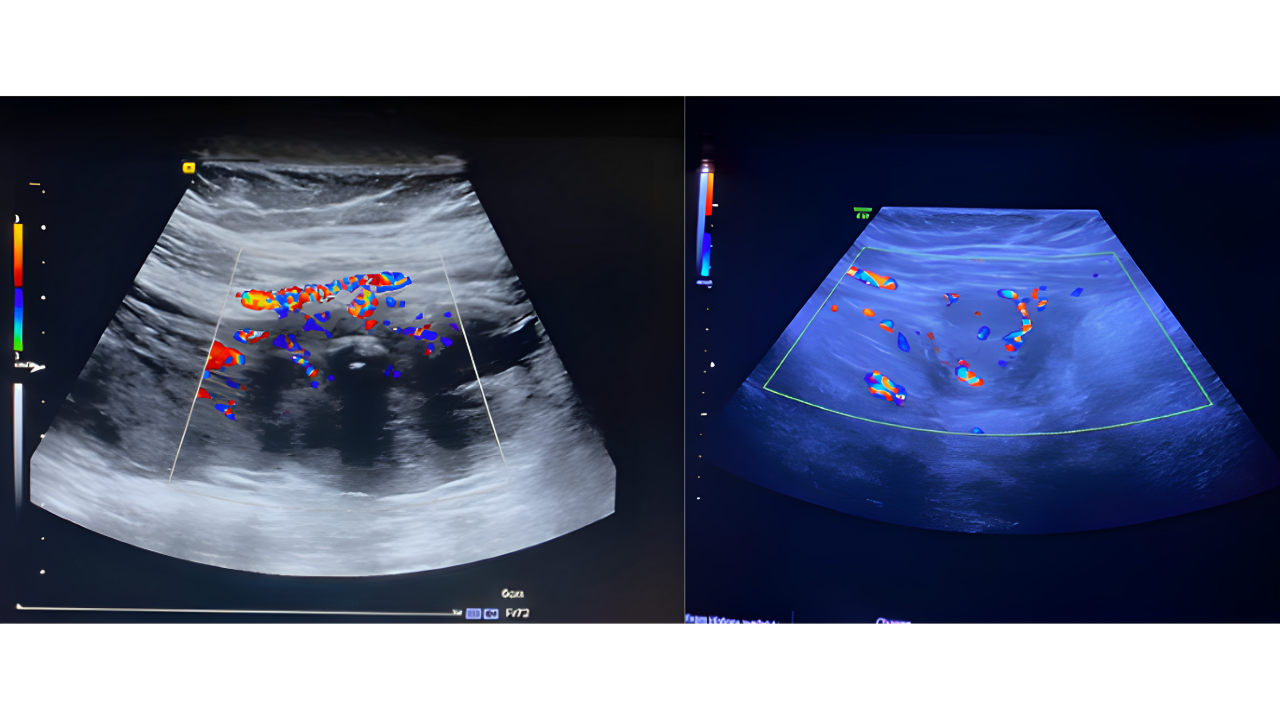
Suture-Induced Tubo-Ovarian Abscess: A Case Report with Literature Review
Huda M. Muhammad, Nahida Hama Ameen Ahmed, Sawen M. Ahmed, Zhiyan M. Mohammed, Meer M....
Introduction
Suture is an underreported cause for tubo-ovarian abscess (TOA) that can cause significant morbidity. This report describes a case of TOA arising from a silk suture three years after bilateral tubal ligation.
Case presentation
A 38-year-old woman with a history of tubal ligation presented with persistent pelvic pain and fever. Imaging revealed a suspicious left adnexal mass with features concerning for malignancy or abscess. Surgical exploration revealed a TOA adherent to surrounding structures, containing a retained silk suture from prior surgery. The abscess and suture were removed, and histopathology confirmed chronic inflammation without malignancy. The patient underwent additional procedures for thorough management, including polypectomy and contralateral tubal ligation.
Literature Review
A total of nine cases of TOAs and suture-induced abscesses were reviewed. Of these, seven were TOAs, six of which occurred postoperatively. Three cases developed following tubal ligation procedures. The abscesses ranged in size from 1 to 7.6 cm. The interval between the presumed inciting event and abscess detection varied widely, with one case presenting more than three decades after surgery. Isolated microorganisms included Escherichia coli, Streptococcus pyogenes, and Peptostreptococcus anaerobius. All patients underwent surgical intervention via various approaches, and several also received adjunctive antibiotic therapy.
Conclusion
Suture-induced TOA following sterilization may result in considerable morbidity, and surgical intervention may provide favorable outcomes.
Letter to the Editor
Annotations on Indeterminate Cytology of Thyroid Nodules in Thyroidology: Novi Sub Sole?
Ilker Sengul, Demet Sengul
Dear Editor,
Indeterminate cytology (IC) remains the most challenging issue for health professionals working in thyroidology, thyroidologists [1-4]. We read a great deal of the article by Ali et al [5]. entitled "Clinicopathological Features of Indeterminate Thyroid Nodules: A Single-center Cross-sectional Study," published in 3rd volume, Barw Medical Journal. This study addresses a challenging and crucial issue by examining the characteristics and malignancy rates of thyroid nodules with IC, the most controversial category for The Bethesda System for Reporting Thyroid Cytopathology (TBSRTC). The authors evaluated the clinicopathological features of the thyroid nodules with Category III, TBSRTC, in a single-center cross-sectional study [5].
One of the strengths of the article is its focus on the challenges in managing IC. Ali and colleagues [5] thoroughly examine comprehensive data, including demographic details, medical history, laboratory tests, preoperative imaging, cytologic evaluation, and histopathological diagnosis. The results indicate a notable malignancy rate in Category III, TBSRTC. Furthermore, the study points out that malignancy tended to be younger, while benign nodules were significantly larger than malignant ones. The study also found a significant association between malignant nodules and Thyroid Imaging Reporting and Data System (TI-RADS) categories 4 and 5 and benign with TI-RADS 2 and 3, which findings align with some existing literature, providing valuable insights into the clinical assessment of IC.
However, several limitations of the study warrant consideration. Firstly, its single-center and retrospective design may limit the generalizability of the findings to diverse populations and settings. As the authors acknowledge, the retrospective data collection might have resulted in missing crucial information. While TI-RADS scoring was provided, more specific ultrasound features of thyroid nodules could have been beneficial. Of note, does including or excluding noninvasive follicular thyroid neoplasm with papillary-like nuclear features (NIFTP), which has been considered a low-risk entity by the current understanding, affect and/or alter the overall results and the assessment of diagnostic performance and study outcome(s)? [2-4] Furthermore, which caliber of the needle had been utilized throughout the study with or without local and/or topical anesthetic agent(s), and would the utilization of thicker or finer needles in order to obtain cytologic samples with or without any local and/or topical anesthesia alter the outcome(s) of this study? [2] Moreover, which edition of TBSRTC has been used for the work and would stress the up-to-date 3rd edition of TBSRTC [3], considering both the novel and crucial subdivisions of category III might affect the study’s relevant outcome(s)? [3,4] Another point of attention is the relatively short data collection period compared to the publication. Finally, while the discussion section compares the findings with various studies in the literature, a more in-depth exploration of the methodological differences and potential discrepancies in results could have been provided. For instance, the conflicting views in the literature regarding the relationship between nodule size and malignancy risk could have been further contrasted with the study's findings. The authors also acknowledge the small sample size as a limitation. For future research, multi-center and prospective studies with detailed imaging, such as elastography and contrast-enhanced sonography, and investigations into the role of molecular markers in thyroid nodules with Category III could improve diagnostic accuracy and potentially reduce unnecessary surgical interventions.
In conclusion, this study significantly contributes to the evaluation of IC in thyroidology despite its limitations. However, considering the noted limitations, further research with more comprehensive and methodologically robust studies in this area is warranted. This issue merits further investigation.
Sincerely,